

Free Chart Friday: The Enterprise AI Operating Stack
Three reports, one scorecard, and who holds the pieces production AI needs

Enterprise AI is crossing from pilots into production, and that transition is what our last three reports have mapped from different angles. Read in order they answer three questions that decide whether a workload ships and who gets paid when it does: whether a sensitive workload can run inside an approved trust boundary at all, who owns the capacity it runs on, and which vendors capture the value as enterprises generate more tokens close to their own data. The scorecard below is where the three lines meet.
The first report started where the capacity models stop. Sizing AI as a supply problem, GPUs, power, packaging, capex, captures how much gets built, not whether the highest-value workloads are allowed to run. The data with the best returns is usually the data legal, compliance, and security teams will not expose to a multi-tenant cloud, so capacity can be financed and energized and still sit unused. We called that second variable permission. The argument was that confidential computing sits on that boundary as a conversion and pricing layer rather than a security line item: hardware-rooted trusted execution plus remote attestation turns trust into an artifact a compliance team can file and an auditor can check, and once that artifact exists, approval behavior changes and blocked workloads become consumed infrastructure. The lift runs two ways in our framework, a trust premium on workloads already heading to cloud and the larger conversion of regulated demand that could not run at any price before, which is why, for this equation particularly, the useful unit moves from tokens per watt to protected tokens per watt and a dollar cleared by compliance should behave differently in a price war than a dollar of experimentation.

The second report took the same permission lens to the supply side and found that AI server demand is no longer one market. Once you model by who owns the hardware rather than where it sits, the buildout separates into three: hyperscaler-owned capacity, the neocloud and third-party AI factory layer, and the enterprise or private AI factory that companies, governments, and regulated industries run inside their own walls. A single GPU cluster financed by a neocloud, contracted by a hyperscaler, consumed by a model lab, and booked by an ODM lands in four reporting streams, and adding them together produces a market that does not physically exist. Our base case carries total demand from roughly $228 billion in 2025 toward $845 billion in 2030, with hyperscalers still the anchor near two-thirds of the market and the marginal dollar of growth migrating outward. The enterprise and private segment is the least observable of the three and the one we hold with the widest range, precisely because its growth is governed by the permission economics the first report priced. That is where the two notes become the same question asked from opposite ends.

The third report went inside that enterprise market and asked who captures the value as token generation moves closer to enterprise data. The workloads that qualify are the persistent ones, agents that run continuously and hold state, retrieval against proprietary corpora, fraud and compliance pipelines, the cases where steady utilization, data sensitivity, latency, and governance line up at once. For those deployments the private AI factory should not be read as a server sale. The server is the entry ticket, and the durable economics sit in what attaches behind it: storage, networking, power and cooling, security, confidential compute, management, software, financing, and services. That reframing turns the investment question into a revenue-quality question, because the same AI server dollar can sit on thin GPU pass-through or pull a higher-quality attach stack behind it, and presence somewhere in that stack is not the same as a strong position in it. Dell and HPE are the cleanest public test cases, and they attack the opportunity from opposite ends, Dell through AI-factory scale and storage pull-through and HPE through a networking-led private-cloud and operations layer. That distinction is the one the scorecard is built to make legible.

Put those three lines together and the question for an enterprise moving into production changes shape. It is not which single venue wins. Production AI runs hybrid and multicloud, across owned capacity, neocloud, and the hyperscalers at once, so the operative question is which vendors hold the operating-stack pieces, the governance, security, data, orchestration, and confidential and sovereign capabilities the series identified, that let an enterprise run agentic AI in production wherever it sits. The scorecard grades eighteen of those capability domains for breadth and ownership on our framework, not for revenue or valuation. Read that way it makes one structural point first: accelerated compute is the only domain where every vendor scores a full three, so the metal is a cleared baseline and the entire spread opens up above it, in exactly the operating and data layers the three reports said decide whether a workload reaches production. Note, this is purely a capability graph not one scoring the quality of the capability.
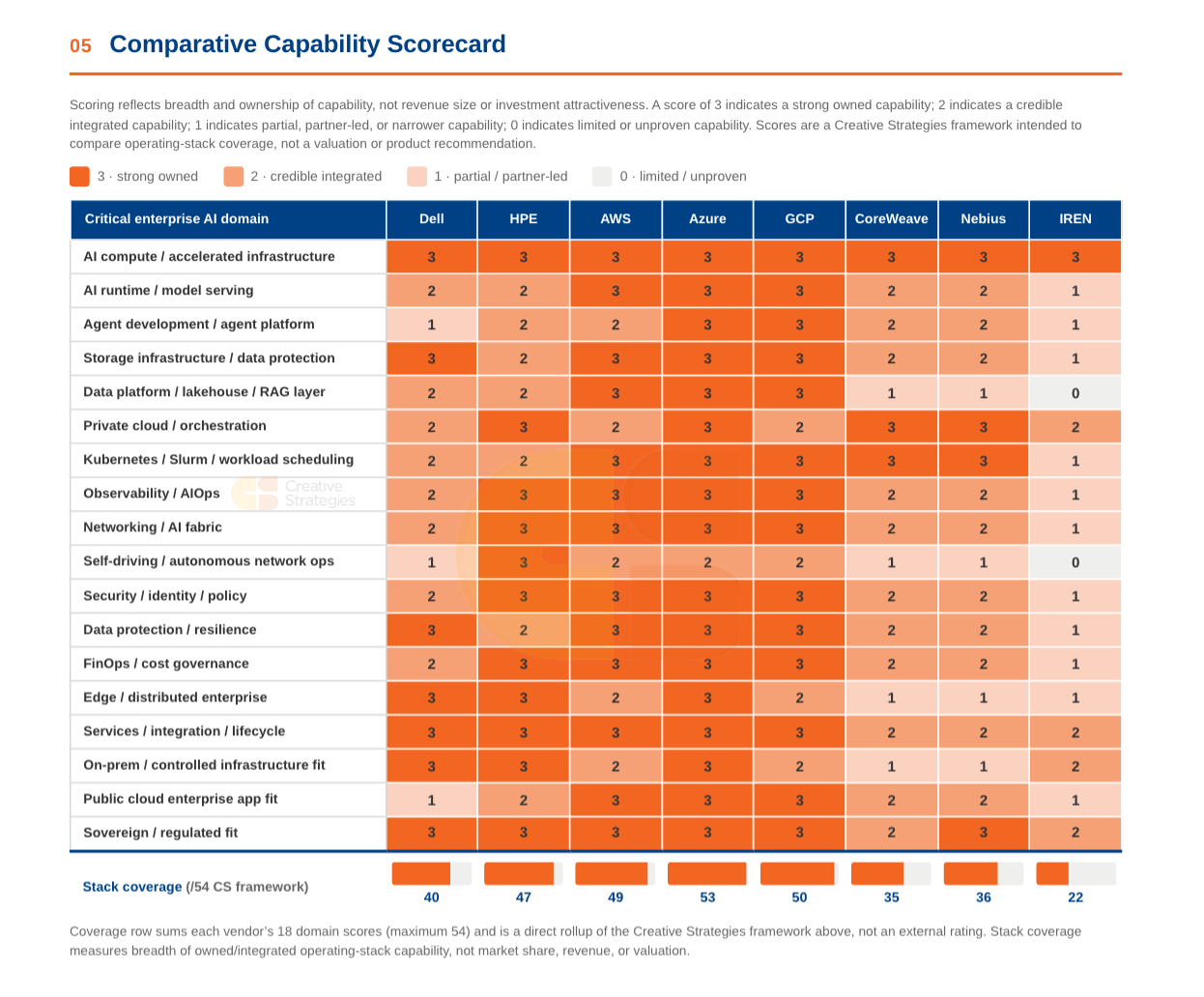
Breadth favors the hyperscalers, with Azure separating at 53 of a possible 54 and its lone soft spot in autonomous network operations, the one domain where HPE scores a three. That same plane explains HPE’s 47 against Dell’s 40, a gap that sits almost entirely in orchestration, observability, networking, security, and FinOps while Dell’s owned strength runs through storage and data-protection resilience, which is the deployable-versus-operable split from the third report rendered as two different shapes rather than one ranking. The AI-native clouds play in a more specific lane for now, with CoreWeave and Nebius strong on compute, orchestration, and scheduling and thin on the data-platform and governance domains that regulated production demands, coverage profiles of 35 and 36 that read as infrastructure depth without enterprise breadth. IREN sits earliest at 22, its strength concentrated in the physical layer with the operating-stack build still ahead of it.
The point we want to land is what stack breadth represents. A vendor with owned or tightly integrated capability across compute, storage, data, networking, security, observability, and cost governance has more ways to capture regulated, sovereign, and enterprise workloads — and more ways to keep the attach revenue around those workloads. That is the line this series has followed from the start: revenue quality improves when the vendor captures more of the operating stack, and deteriorates when AI infrastructure remains a hardware pass-through cycle.
The scorecard is the compressed version of that argument. As production AI moves into a hybrid and multicloud world, the winning stacks will be the ones that make token generation governable, secure, metered, operable, and recoverable. The hardware still matters. The question is who owns enough of the environment around it to make the revenue durable.